Ottima proposta, ci sono.
Secondo me lo “stato” dovrebbe avere un luogo “certificato” in cui ci siano i dati e sperabilmente anche i servizi, i metadati e qualche pipeline.
Faccio un esempio di pipeline.
Ho dei dataset sulla differenziata nei comuni e ho la fortuna che sia già associato il codice ISTAT. TOP!
Allora, parto dalla fonte forse più autorevole oggi per i Comuni, ovvero ANPR e in particolare questo file, che ha pure un URL permanente (vedi qui), faccio un semplice JOIN e sono pronto per fare mappe, grafici, ecc.
Tra le cose che metterò in piedi ci sarà pure un grafico aggregato per regioni. Il file ANPR mi consente di farlo, perché ci sono i codici regione. Ma nel grafico non posso stampare come etichetta “19”, devo inserire “Sicilia”.
Mi serve a corredo un endpoint (che sia un servizio o un altro file con un URL statico), in cui per i codici sovracomunali ho le “coppie” codici-label. Mi sembra che il punto di partenza debba/possa essere questa pagina ISTAT https://www.istat.it/it/archivio/6789.
La prima cosa che mi chiedo è: posso dare per scontato che quando c’è un aggiornamento, ANPR e ISTAT siano allineati? La domanda è retorica e credo di no, derivano da flussi diversi.
Poi osservo alcune cose:
- il file sui “Codici statistici e denominazioni delle ripartizioni sovracomunali” è pubblicato come zip; sarebbe molto più comodo un puntamento diretto alla risorsa;
- al file CSV non è associata alcuna info sull’encoding. Rimuoverei l’esigenza costante di fare inferencing dell’encoding e di base andrei verso quello che è lo standard di fatto, ovvero UTF-8 (così di default qualsiasi import/read funzionerà);
- al file CSV non è associata alcuna info sul separatore. Rimuoverei l’esigenza costante di fare inferencing sul separatore e di base andrei verso la
,che è lo standard di fatto (così di default qualsiasi import/read funzionerà); - rimuoverei gli “a capo” dal nome dei campi

- pubblicherei i numeri come numeri e non come stringhe
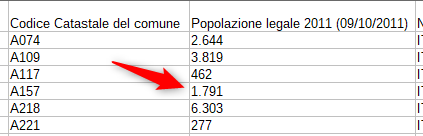
- assocerei al nome del file (o lo metterei in un campo, o in un metadata a corredo) la data di aggiornamento del dataset.
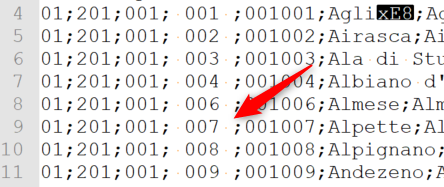
Ma in questo dataset in ogni caso non ci sono i nome delle regioni. Allora ho come alternativa il file gemello di quello ANPR: Elenco dei comuni italiani.csv.
Vale tutto quanto detto prima, su encoding, separatori, ritorni a capo. Qui si aggiunge la presenza di whitespace errati.
 .
.
Qui trovo il nome regione e posso mettere via JOIN l’etichetta giusta.
Torno a ANPR e voglio fare una mappetta per comuni. Come etichetta non metterò il codice ISTAT, ma il nome del Comune. Ma è brutto scrivere ACQUAVIVA D'ISERNIA, perché non voglio urlare. E per i mestieri che hanno a che fare con i dati, avere anche un’etichetta “normalizzata” è un’esigenza standard. Ok, faccio il JOIN con ISTAT e le prendo da lì; sono allineati?
Sono stato lungo, perché non avevo molto tempo, ma volevo mettere alcuni punti esperenziali sul piatto.
Avere delle API come quelle di WikiData, che mettano in fila e rispondano a queste e altre esigenze classiche, è un servizio che mi aspetterei che fosse “statale” (mi cito anche io).
Ale, grazie